
HRNet中科大的论文,2D人体姿态检测。我们将尝试将其运用于目标检测和实例分割,与Mask R-CNN结合。
目前存在的姿态检测方法都是从高分辨率下采样至低分辨率,然后从低分辨率恢复至高分辨率。但HRNet保留了高分辨率网络,向高分辨率主网络逐渐并行加入低分辨率子网络,于是预测的关键点热度图就会更加准确。
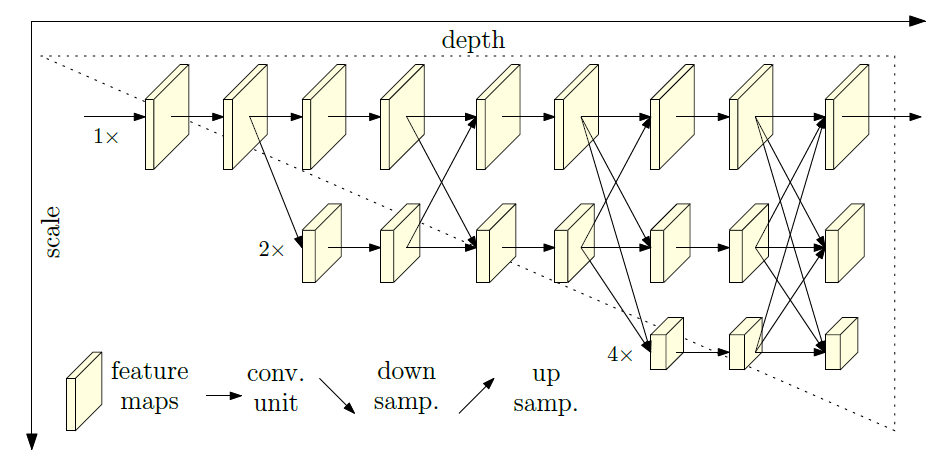
用$\mathcal{N}_{sr}$表示第$s$阶段(stage),代表第$r$个分辨率尺度的子网络,传统的序列(线性)结构是这样的:
\begin{equation}
\begin{array}
\mathcal{N}_{11} & \rightarrow ~~ \mathcal{N}_{22} &\rightarrow ~~ \mathcal{N}_{33} & \rightarrow ~~ \mathcal{N}_{44}
\end{array}
\end{equation}
而本文采用的并列结构是这样的:
\begin{equation}
\begin{array}
\mathcal{N}_{11} & \rightarrow ~~ \mathcal{N}_{21} &\rightarrow ~~ \mathcal{N}_{31} & \rightarrow ~~ \mathcal{N}_{41} \\
& \searrow ~~ \mathcal{N}_{22} &\rightarrow ~~ \mathcal{N}_{32} & \rightarrow ~~ \mathcal{N}_{42} \\
& &\searrow ~~ \mathcal{N}_{33} & \rightarrow ~~ \mathcal{N}_{43} \\
& & & \searrow ~~ \mathcal{N}_{44}
\end{array}
\end{equation}
横向深度增加,纵向尺度增加。每一个阶段(上面每一列)被分成了若干个交换块(exchange block),在每个交换块中,一个交换单元(exchange unit)连接所有并列的卷积单元。下面是一个阶段中的结构示例:
\begin{equation}
\begin{array}
\mathcal{C}^1_{31} & \searrow &\nearrow ~~ \mathcal{C}^2_{31} & \searrow &\nearrow ~~ \mathcal{C}^3_{31} & \searrow \\
\mathcal{C}^1_{32} & \rightarrow ~~ \mathcal{E}^1_{3} & \rightarrow ~~ \mathcal{C}^2_{32} & \rightarrow ~~ \mathcal{E}^2_{3} & \rightarrow ~~ \mathcal{C}^3_{32} & \rightarrow ~~ \mathcal{E}^3_{3}\\
\mathcal{C}^1_{33} & \nearrow &\searrow ~~ \mathcal{C}^2_{33} & \nearrow &\searrow ~~ \mathcal{C}^3_{33} & \nearrow\\
\end{array}
\end{equation}
其中$\mathcal{E}^{b}_{s}$表示第$s$阶段(stage)的第$b$个交换块,$\mathcal{C}^{b}_{sr}$是其中代表第$r$个分辨率尺度的卷积单元。交换单元的工作原理如下图:
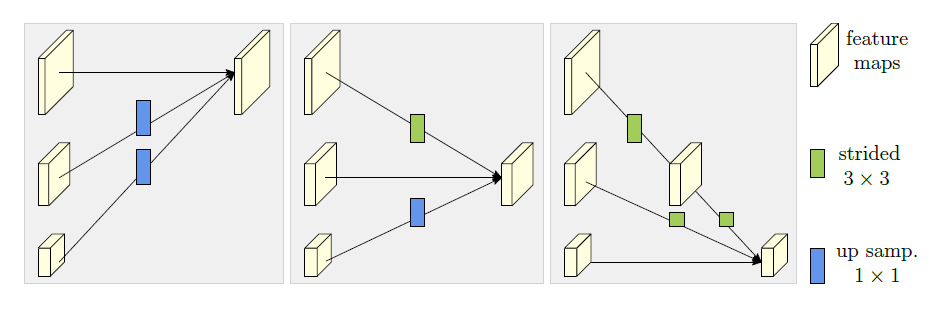
上采样是$1\times 1$的最近邻点差值,下采样是若干个步长为$2$的$3\times 3$卷积层。
实例分割。在图片中检测物体同时为每个检测出的实例生成一个segmentation mask。在Faster R-CNN的识别bounding-box分支基础上增加了一个在每个关注区域(RoI)上预测segmentation mask的分支。这个新分支是一个小的全卷积网络,逐个像素地预测mask。
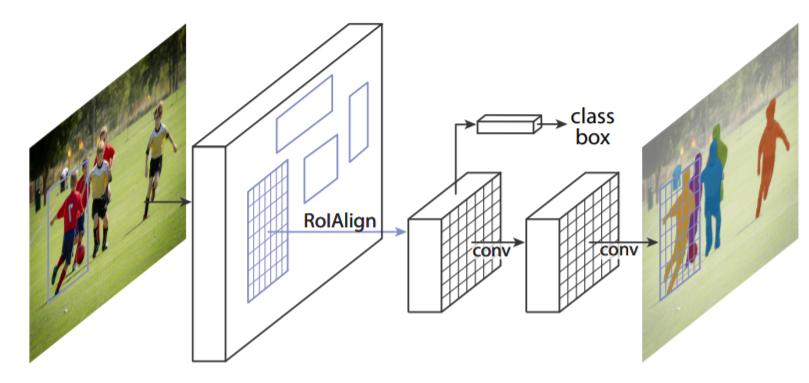
为了解决对齐(空间量化)误差的问题,Mask R-CNN将Faster R-CNN中的RoiPool改进为RoiAlign。
Mask R-CNN将mask和分类预测解耦,即为每个分类单独预测一个二进制mask。每个分类之间没有竞争,而是依靠RoI的分类来判断每个像素属于哪个分类。
Faster R-CNN有两个输出:分类和bounding-box,我们加入的新分支输出mask。但是mask与前两个不同,需要更精细的空间信息,所以我们采用逐像素对齐(pixel-to-pixel alignment)。
Faster R-CNN的检测过程分为两个阶段:第一阶段是区域推荐网络(RPN),推荐候选bounding-box。第二阶段在每个候选box上用RoiPool来做分类和回归。Mask R-CNN也分为两个阶段:第一阶段同样是RPN。第二阶段除了分类和回归,还需要为每个RoI输出一个mask。
为每个PoI用全卷积网络预测一个$m\times m$的mask,卷积网络逐像素对应的特点可以更好地提取空间结构,不像之前的模型用全连接层来预测mask,结果会坍缩成短的向量。
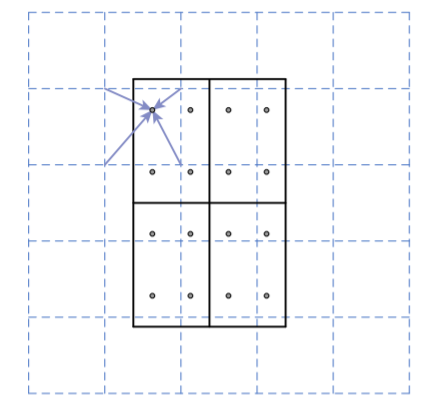
RoIPool分割feature map时采用的是四舍五入取整,会带来误差。RoiAlign不进行取整,用双线性插值计算每个采样点处于的PoI区域四个格点上取值的和或均值。如下图所示。
网络包含两个部分:提取图像特征的卷积backbone网络和识别bounding-box的head网络。关于backbone网络,文章尝试了ResNet/ResNeXt-50/101-C4/FPN(Feature Pyramid Network)的多种组合。而head网络就是在Faster R-CNN结构的基础上加上mask分支,如下图。
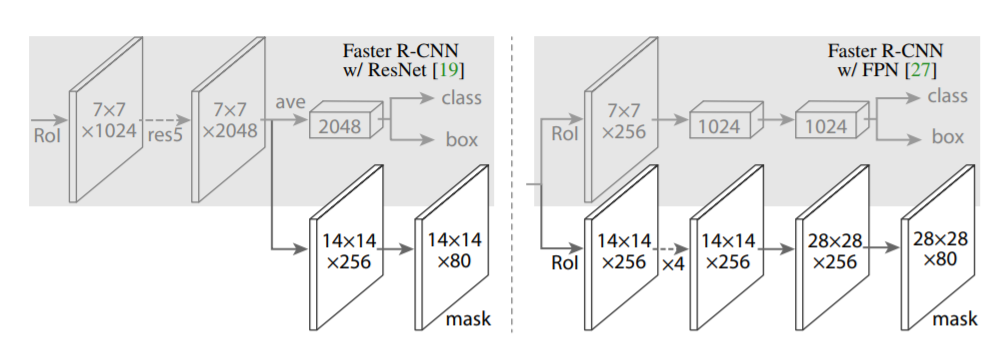
左边是用ResNet-C4做backbone的head网络,右边是用FPN做backbone的head网络。横向箭头是卷积,扩大map大小的箭头是反卷积。