深度神经网络(DNN)目前最大的问题就是缺少transparency,无法保证对于未验证的输入,模型会输出什么结果,因此就会出现一些backdoors。这篇文章就是要找出造成误分类的trigger,并且找到保护的办法。
Backdoor Attack和Adversarial Attack的区别:后者只是更改特定的图片,前者是在任意样本中加入trigger,可以把不同标签的数据误分类成目标分类。而且backdoor必须被植入模型当中。
攻击模型与之前的BadNets和Trojan Attack相同,保护的方式分为三个目标:检测backdoor、识别backdoor、减弱backdoor。检测backdoor含有的signature需要它们很强的因果关系,但是目前的研究缺少这方面的结果,所以很难。首先,在输入图片中扫描trigger很困难,因为trigger可以是任意形状,也可以被设计成避免检测。其次,通过分析DNN的内部结构来寻找中间层的异常也很困难。Trojan Attack这篇论文中提出了观察错误分类的结果的方法,但是backdoor不一定会体现出一个一致的趋势,因此这个方法并不可行。
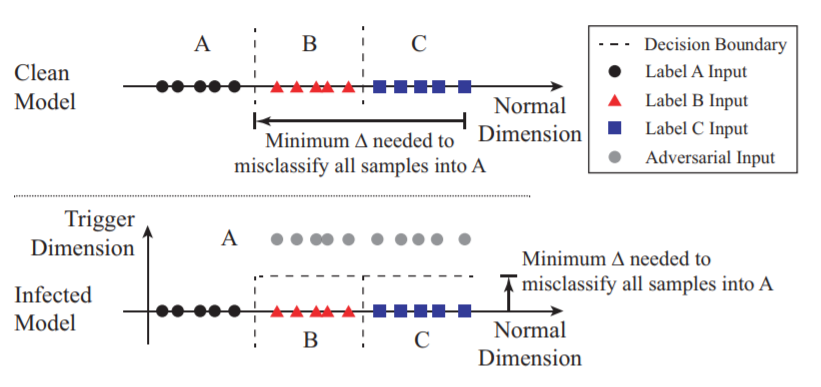
保护的思路就是建立一个新的trigger维度。如下图所示,传统的方法就是根据一维数据的大小范围来分类,增加了第二维之后,这个分类的范围变成了一个区域,含有trigger的图片在新的维度会有更高的值,所以被分隔在了区域外,因此被误分类成了A。增加了新的维度之后,想要将其他所有数据误分类为A,只需要在竖直距离上移动,需要的代价更小。