如何更好地恢复图像的纹理细节。这是CNN方法没有解决的。
最优化目标函数作为监督,以均方差(MSE)作为目标函数进行优化,减小均方差,增大信噪比(PSNR)。但是MSE和PSNR值的高低并不能很好的表示视觉效果的好坏。
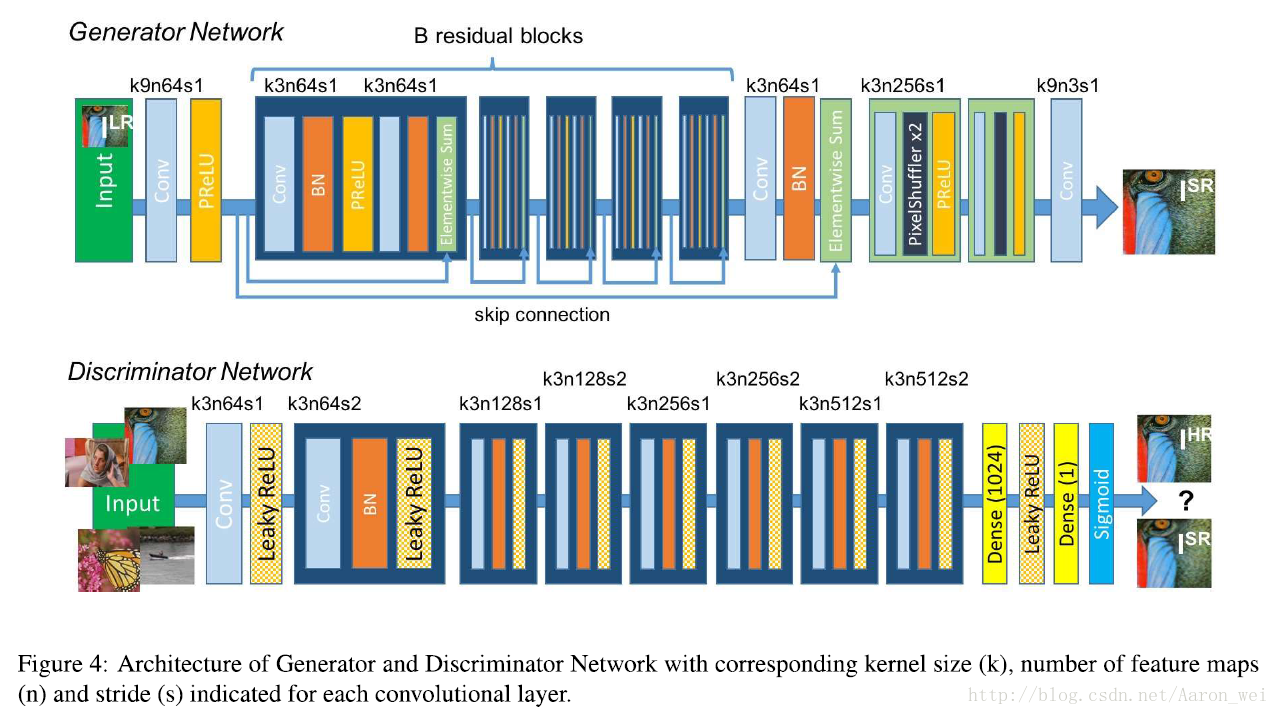
由Adversarial Loss和Content Loss组成的Perceputal Loss Function。 其中Adversarial Loss由判别器生成,使我们生成的图像更加接近自然图像;Content Loss由图像的视觉相似性生成,而不是像素空间的相似性。采用Mean-Opinion-Score(MOS)测试作为图像效果的评判,最后的测试结果表明采用SRGAN获得的图像的MOS值比采用其他顶级的方法获得的图像的MOS值更加接近原始的高分辨图像。
深度残差网络(ResNet),优化目标除了MSE,还有一种由VGG网络和判别器构成的新型Perceptual Loss。其中判别器可以使结果更接近用作ground-truth的高分辨率图像。VGG网络在其他论文中提出,作者用VGG网络特征图谱的损失函数取代了以MSE为基础的Content Loss。
训练一个以$\theta_G$为参数的前馈神经网络,$\theta_G$代表$L$层深度网络的weights和biases。训练方程:
$$\hat{\theta_G}=\text{arg}\min\limits_{\theta_G} \frac{1}{N}\sum_{n=1}^N l^{SR}(G_{\theta_G}(I_n^{LR}),I_n^{HR})$$
$l^{SR}$表示Perceptual Loss。
判别器$D_{\theta_G}$,生成器和判别器交替优化下式:
$$\min\limits_{\theta_G}\max\limits_{\theta_D}\mathbb{E}_{I^{HR}\sim p_{\text{train}}\left(I^{HR}\right)}\left[logD_{\theta_D}\left(I^{HR}\right)\right]+\mathbb{E}_{I^{LR}\sim p_{G}\left(I^{LR}\right)}\left[log\left(1-D_{\theta_D}\left(G_{\theta_G}\left(I^{LR}\right)\right)\right)\right]$$
网络结构:
新型Perceptual Loss Function (Content Loss + Adversarial Loss):
$$l^{SR} = \underbrace{ \underbrace{l_{X}^{SR}}_{\text{Content Loss}} + \underbrace{10^{-3}l_{\text{Gen}}^{SR}}_{\text{Adversarial Loss}} }_{\text{Perceptual Loss (for VGG based content losses)}}$$
- Content Loss
以前用MSE作损失函数的Content Loss与新的以预训练19层VGG网络ReLU激活层为基础的VGG Loss:
$$l^{SR}_{MSE}=\frac{1}{r^2WH}\sum_{x=1}^{rW}\sum_{y=1}^{rH}\left(I^{HR}_{x,y} - G_{\theta_G}\left(I^{LR}\right)_{x,y}\right)^2$$
$$l^{SR}_{VGG/i,j}=\frac{1}{W_{i,j}H_{i,j}}\sum_{x=1}^{W_{i,j}}\sum_{y=1}^{H_{i,j}}\left(\phi_{i,j}\left(I^{HR}\right)_{x,y}-\phi_{i,j}\left(G_{\theta_G}\left(I^{LR}\right)\right)_{x,y}\right)^2$$
其中$\phi_{i,j}$表示VGG19网络当中第$i$层max pooling层后的第$j$个卷积层得到的特征图谱。
$W_{i,j}$和$H_{i,j}$分别表示VGG网络中特征图谱的维度。
- Adversarial Loss
通过“欺骗”判别器从而偏向生成输出更接近自然图像的输出。
$$l_{Gen}^{SR}=\sum_{n=1}^{N}-logD_{\theta_D}(G_{\theta_G}(I^{LR}))$$
其中$D_{\theta_D}(G_{\theta_G}(I^{LR}))$表示的是判别器将生成器生成的图像判定为自然图像的概率。
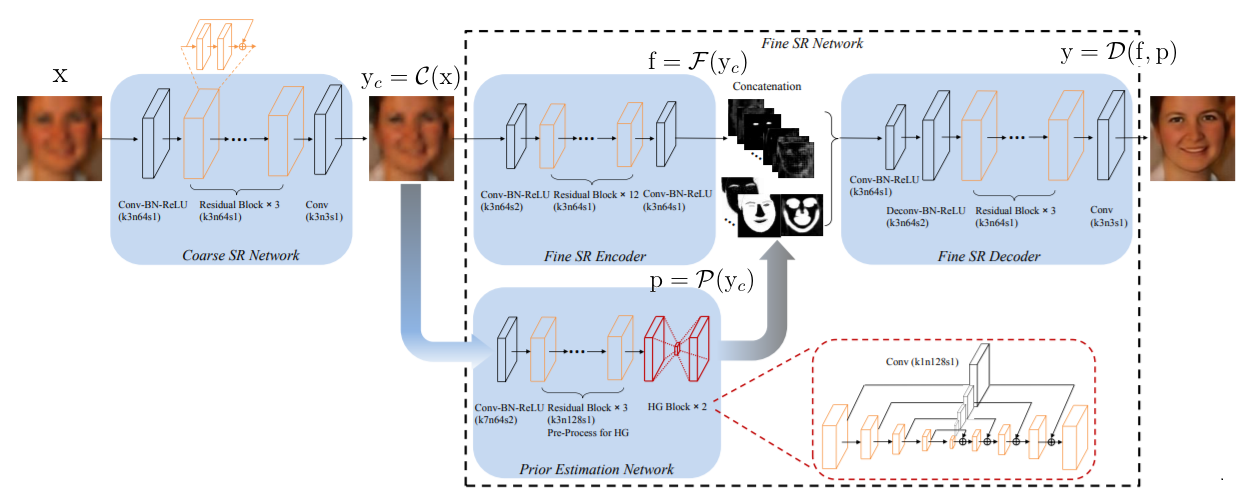
首先是一个粗糙超分辨率网络,生成一个粗糙的HR图像。然后将粗糙HR图像分别输入到两个分支:精密超分辨率编码器和先验信息估测网络。前者抓取图像的特征,后者对人脸的landmark和heatmap等信息做出估计。得到的图像特征和先验信息都被输入到精密超分辨率解码器中来还原HR图像。粗糙超分辨率网络后面的三个部分统称为精密超分辨率网络。FSRNet还加入了FSRGAN得到的Adversarial Loss,有助于生成更真实的人脸图像。
两个有关的任务:人脸对齐和人脸解析。这是两个人脸超分辨率的新型评价指标,与传统的通过视觉感知来评价不同。
- Coarse SR Network
从原图像$\mathrm{x}$恢复一个粗糙的超分辨率图像$\mathrm{y}_c$,避免输入图像太过模糊无法进行先验估测。
$$\mathrm{y}_c=\mathcal{C}(\mathrm{x})$$
细节:一个3×3的卷积层→3个残差块→另一个3×3的卷积层。
- Prior Estimation Network & Fine SR Encoder
$$\mathrm{p}=\mathcal{P}(\mathrm{y}_c),\mathrm{f}=\mathcal{F}(\mathrm{y}_c)$$
其中$\mathrm{f}$是编码器抽取出的特征,$\mathrm{p}$是估测网络得到的先验信息。
任何真实物体的形状和纹理都有不同的分布,但我们选择刻画人脸的形状先验。原因有两点:1.在降低分辨率时形状会比纹理更好地保留,因此做超分辨率时也更容易取出;2.形状先验要比纹理先验更容易表示,对于人脸,人脸解析可以找出面部各部分的划分,landmark可以给出面部关键点精确的定位,这些都代表形状信息。而纹理信息就不好表示。
采用沙漏结构估测面部关键点热图并解析成先验估测网络。这个沙漏结构看不太懂,需要看论文[Stacked hourglass networks for human pose estimation]
编码器利用残差块来做特征抽取。先验特征已经被下采样为64×64,为了使feature的大小一致,编码器用大小3×3,步长为2的卷积层将feature map下采样为64×64,然后用ResNet的结构来抽取图像特征。
- Fine SR Decoder
$$\mathrm{y}=\mathcal{D}(\mathrm{f},\mathrm{p})$$
$\mathrm{y}$就是最终得到的超分辨率结果图片。
首先,先验信息$\mathrm{p}$和图像特征$\mathrm{f}$被连接在一起作为解码器的输入,然后用3×3的卷积层将feature map数量降为64,又用4×4的反卷积层将feature map上采样为128×128,接下来是3个残差块,用来解码特征,最后一层还是3×3的卷积层,用来还原图片。
- Loss Function
给定$N$个样本的训练集$\{\mathrm{x}^{(i)},\tilde{\mathrm{y}}^{(i)},\tilde{\mathrm{p}}^{(i)}\}_{i=1}^{N}$,其中$\mathrm{x}^{(i)}$是LR图像,其对应的ground-truth HR图像为$\tilde{\mathrm{y}}^{(i)}$,$\tilde{\mathrm{p}}^{(i)}$是对应的ground-truth先验信息。FSRNet的损失函数如下:
$$\mathcal{L}_{\mathrm{F}}(\Theta)=\frac{1}{2N}\sum_{i=1}^{N}\{||\tilde{\mathrm{y}}^{(i)}-\mathrm{y}_{c}^{(i)}||^2+\alpha||\tilde{\mathrm{y}}^{(i)}-\mathrm{y}^{(i)}||^2+\beta||\tilde{\mathrm{p}}^{(i)}-\mathrm{p}^{(i)}||^2\}$$
其中$\Theta$是参数集,$\alpha$和$\beta$是两个参数,分别代表括号中第二项“粗糙超分辨率损失”以及第三项“先验损失”的权重,$\mathrm{y}^{(i)}和\mathrm{p}^{(i)}$分别是第$i$张图片的超分辨率结果和估测出的先验信息。
- FSRGAN
主要思想是用判别网络区分超分辨率图像和真实的高分辨率图像,以此训练超分辨率网络来“欺骗”判别器。
对抗网络$\mathrm{C}$的目标函数:
$$\mathcal{L}_{\mathrm{C}}(\mathrm{F},\mathrm{C})=\mathbb{E}\left[log\mathrm{C}(\tilde{\mathrm{y}},\mathrm{x})\right]+\mathbb{E}\left[log(1-\mathrm{C}(\mathrm{F}(\mathrm{x}),\mathrm{x}))\right]$$
$\mathrm{C}$输出的是输入图片为真实图片的概率,$\mathbb{E}$是概率分布的期望。此外,还有一种使用预训练VGG-16网络中高层feature map(‘relu5_3’层的特征)的Perceptual Loss,可以帮助评估与感知有关的特征,函数如下:
$$\mathcal{L}_{\mathrm{P}}=||\phi(\mathrm{y})-\phi(\mathrm{\tilde{y}})||^2$$
其中$\phi$指固定的预训练VGG模型,将图片$\mathrm{y}/\mathrm{\tilde{y}}$映射到特征空间中。这样,我们得到了FSRGAN的最终目标函数:
$$\text{arg}\min\limits_{\mathrm{F}}\max\limits_{\mathrm{C}}\mathcal{L}_{\mathrm{F}}(\Theta)+\gamma_{\mathrm{C}}\mathcal{L}_{\mathrm{C}}(\mathrm{F},\mathrm{C})+\gamma_{\mathrm{P}}\mathcal{L}_{\mathrm{P}}$$
其中$\gamma_{\mathrm{C}}$和$\gamma_{\mathrm{P}}$分别代表GAN和Perceptual Loss的权重。
许多方法将多图片假设成同一场景的不同视角,可以看作多图像SR,利用显示冗余信息。而本文的方法是单图像SR(SISR),利用隐式冗余信息。
流行的SISR方法可以分为基于边缘、基于图像统计、基于patch,以及基于稀疏度。基于稀疏度的方法是将图像编码成一些原子图片的组合,之后通过训练将LR和HR对应起来。但是这个方法的缺点是通过非线性重建来加入稀疏度限制需要花费很大计算量。
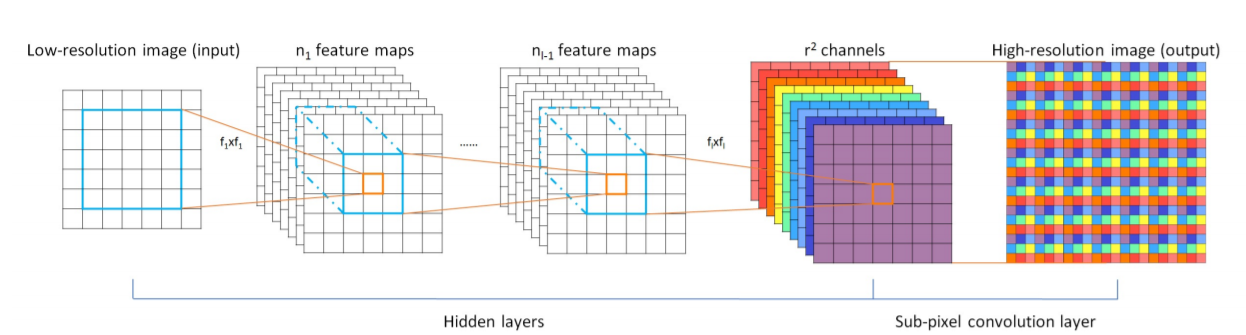
这篇文章所用网络的结构如图所示。先提取LR图像的$r^2$个通道feature map,最后再进行上采样。前面是$l$层的CNN,最后一层是一个“亚像素卷积层(ESPCN)”,每一步将$H\times W\times C\cdot r^2$的特征图像按图中的方法重新排列(shuffle)成$rH\times rW \times C$。

在对抗训练进行视频超分辨率中,用向量范数作为损失函数可以带来时间流畅性和连贯性,但是会损失空间细节。本文介绍的方法能兼顾时间和空间。除了对抗学习所用的判别器以外,文中新引入了一个叫“Ping-Pong”的损失函数,在不影响视觉质量的前提下有效去除时间上的失真。本文提出了一系列衡量准确度以及视觉质量的方法。
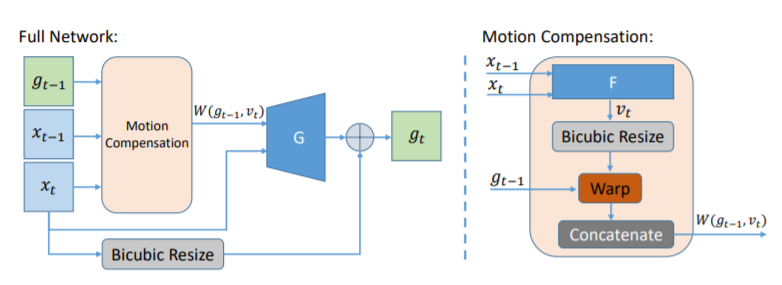
模型包含三个部分:循环生成器$G$、流估测网络$F$、时空判别器$D$。流估测网络学习帧之间的运动补偿,同时帮助生成器和判别器。训练过程中,$G$和$F$同时训练来欺骗判别器$D$。
循环生成器$G$和流估测网络$F$的结构如下图所示,$G$通过LR图像$x_t$生成HR图像$g_t$,并且循环使用上一步的HR图像$g_{t-1}$。$F$估测LR图像$x_{t-1}$和$x_t$之间的运动$v_t$,经过缩放之后在HR图像之间同样适用,将$g_{t-1}$变为扭曲后的帧$W(g_{t-1}, v_t)$。与以前的方法不同,这两个网络学习的是图像剩余,也就是HR图像和双立方插值后的LR图像的差别,学习剩余可以使训练过程更加稳定。
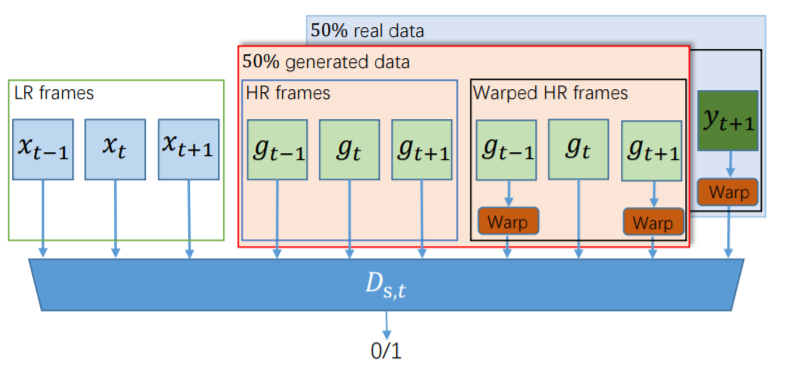
时空判别器$D$的结构如下图所示,接收三张连续图像的三元组,50%的真实数据和50%的生成数据混合,然后做出判断$0$或$1$。
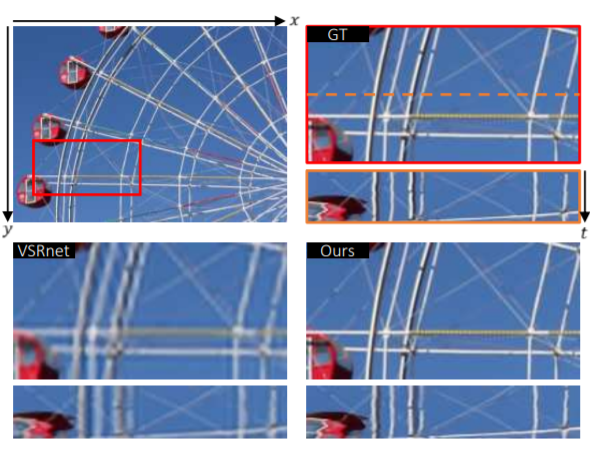
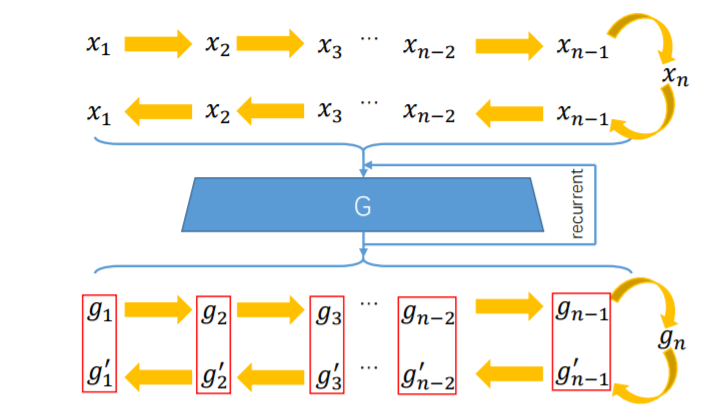
文中提出对抗结构会造成一种“漂移”的问题,大概就是空间细节缺失。因此他们新提出了一种损失函数“Ping-Pong Loss”,如下图所示。原理就是生成的高分辨率帧$g_t$应该与输入帧序列是正向还是反向无关,因此如果将输入帧序列反向,结果$g’_t$应该与$g_t$相同。Ping-Pong Loss即为计算所有$g_t$和$g’_t$差值的二范数之和。
$$\mathcal{L}_{pp}=\sum_{i=1}^{n-1}||g_t-g’_t||_2$$

视频超分辨率(VSR)可以逐帧采用单图片超分辨率的网络完成,但是帧之间并没有时间相关性(temporal relationship),所以很可能连续的帧之间连接不自然,造成闪烁失真(flickering artifact)。
传统的VSR算法都包含两个步骤:1.动作估测及补偿;2.上采样。其存在的问题是结果过于依赖精确的动作估测,还有输出的高分辨率图像是由很多个动作补偿后的低分辨率图像混合经过CNN得到的,这样可能使高分辨率图像出现模糊。
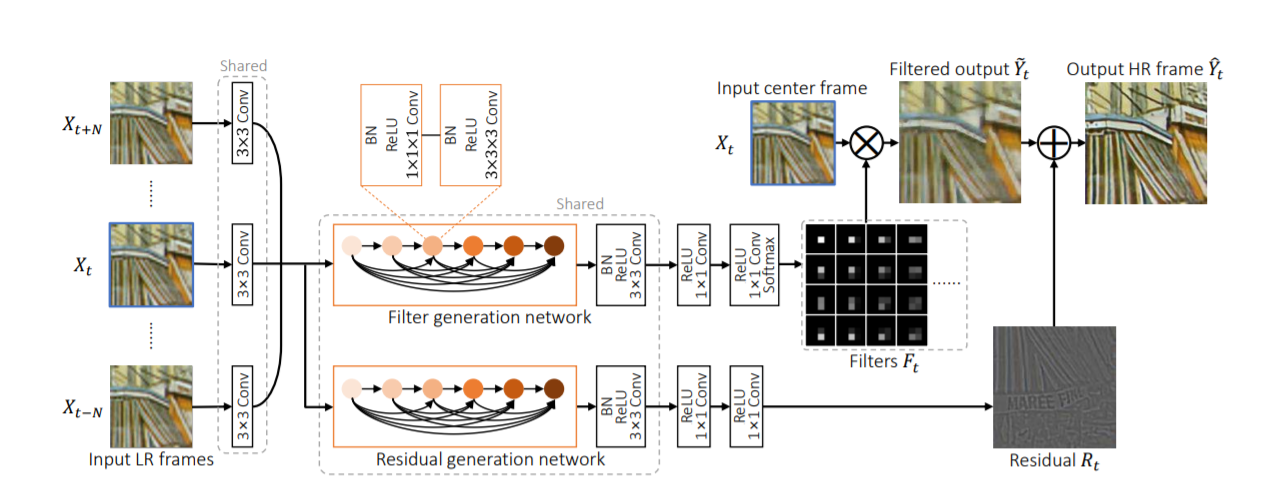
这篇论文提出了一个新的端到端深度神经网络模型,与之前的方法有根本的差别。这个模型并没有显式地计算相邻帧之间的动作补偿,而是隐式运用了动作信息来生成“动态上采样滤镜(dynamic upsampling filters)”。生成的每张高分辨率图像是由一张低分辨率图像(input center frame)经过一系列filters得到的,如下图所示,并不直接结合多个图像的信息,因此最终可以得到更清晰、时间一致的高分辨率视频。
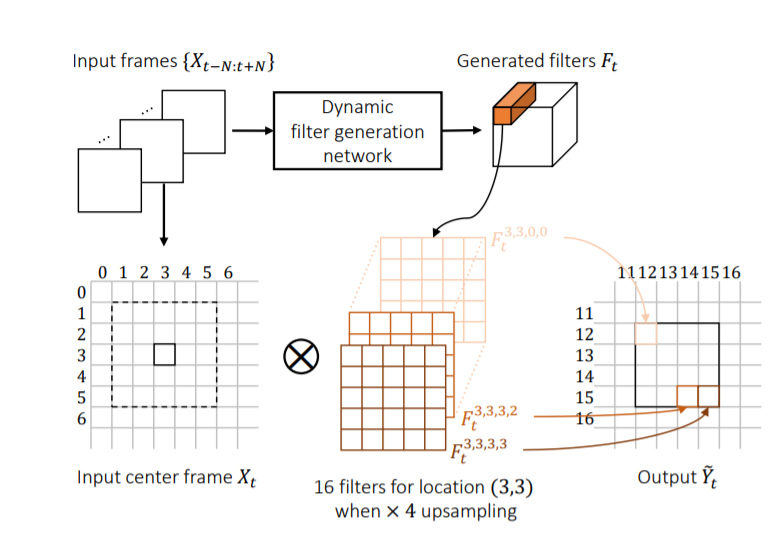
为了得到动态上采样滤镜,提出了Dynamic Filter Network(DFN),输入一系列连续的低分辨率图像帧集合${X_{t-N:t+N}}$,假设要将$H\times W$的图像超分辨率至$rH\times rW$,输出$r^2HW$个filter,每个低分辨率图像中的像素点$(x,y)$对应$r^2$个filter,记为$F_t^{x,y,i,j}$,用来生成目标高分辨率图像中的$r^2$个像素。filter的大小可以任意确定,这篇论文中用的是$5\times 5$,那么像素点$(x,y)$周围的$5\times 5$区域与每一个filter做点积,然后再加上同样方法训练出的剩余图,就得到了最终的输出图片的$r^2$个像素。另外,为了保留时空信息,将2D卷积层改为了3D卷积层。
除了filter外,还需要加一个residual剩余图,其中包含图像高频的细节。生成residual的网络和和生成filter的网络结构基本一致,参数也是共享的。具体网络结构由下图所示。